上一篇文章中提到了關於棒球賽的改善策略以及針對改善策略的監控結果。這篇文章主要想分享的是在整個事件中額外觀察到的一些值得分享的兩件事情。
第一件事情主要是技術上的發現,請見下面四張圖:
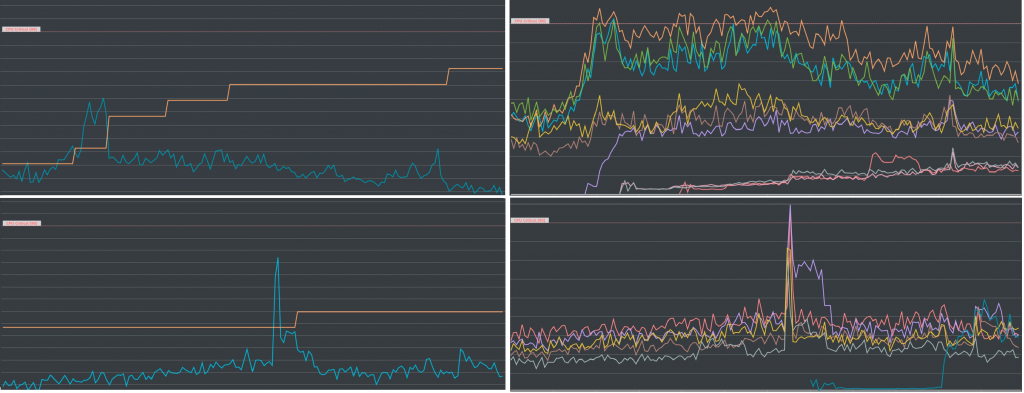
x 軸都是時間。上面兩張圖代表的是沒有預先加開機器的狀況,下面的兩張圖則是有預先加開機器的狀況。左邊的兩張圖代表資料庫伺服器的數量以及平均 CPU 的使用狀況。右邊兩張圖則是把單一資料庫的 CPU 使用狀況拿出來各別檢視的狀況。上面兩張與下面兩張,雖然是兩個不同的棒球賽,但是兩場棒球賽的條件,包含湧進來的人數以及速度都沒有差非常多。
我們可以比較左邊兩張圖的狀況,因為上面沒有預先加開伺服器,因此可以觀察到黃色線一開始是比較低的。 任何讓我注意到的事情,則是伺服器的數量最後成長到了原本的大約三到四倍左右。 相較而言,下面那張圖雖然一開始因為有預先加開伺服器,因此黃色的線比較高,但一直到最後都維持相對平穩的伺服器數量,只有在中間可能某個球賽的高潮的時候而多開了一台伺服器。奇怪的事情是,明明人數沒有差那麼多,但為什麼前者所需要的伺服器數量最後卻遠高過後者的伺服器呢?
請再看右邊的那兩張圖,我們把單一資料庫伺服器的 CPU 使用量攤開來之後, 發現在有預先加開伺服器的情況之下(下面那張圖),每一個伺服器的 CPU 使用量看起來相當的平均;然而在沒有預先加開伺服器的情況下, 一開始就存在的伺服器持續處在忙不過來的狀態( CPU 90% 且警報一直在響),新加開的資料庫伺服器看起來好像有點閒( CPU 處在 40-50% 左右),而更晚加開的伺服器們則看起來在偷懶(只有 10-20% )!
為什麼會發生這樣的狀況呢?是不是因為我們的負載平衡機制發生了一些問題,導致流量沒有被平均分散到各個伺服器呢?然而筆者認為,其實正是因為我們的負載平衡有非常平均的分散流量,才會導致這個狀況。請見下圖:
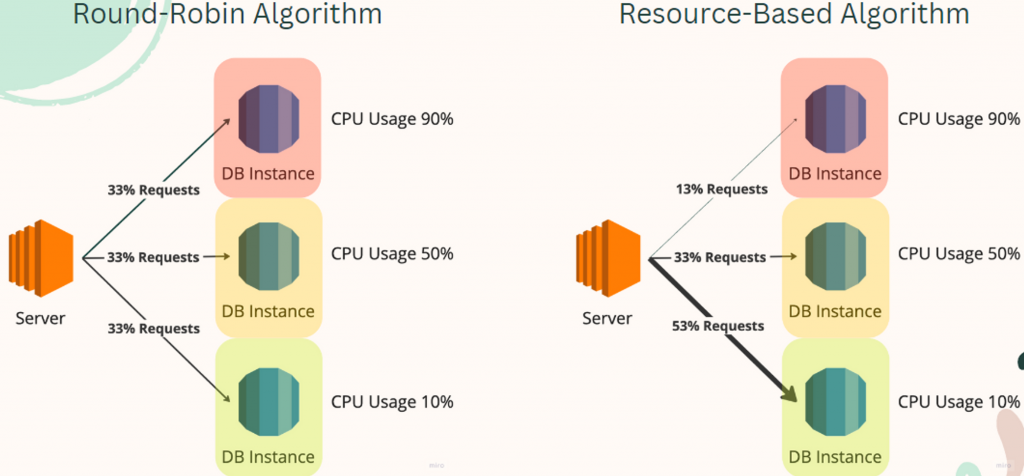
請讀者試著想像一下,假設現在我們沒有預先加開伺服器,且流量剛衝進來,導致我們一開始就存在的伺服器已經接近滿載,並觸發了自動擴展的機制。這個時候比較理想的負載平衡演算法,應該是把大部分的流量導向新開的伺服器,對嗎?畢竟舊的伺服器已經滿載了,應該由新的伺服器來接手接下來大部分的流量才對。也就是上圖右半,跟據資料使用狀況而出現的負載平衡演算法。但實際上我們使用的是左邊的,最陽春的演算法。因為請求無論如何都被平均分散,因此已經滿載的就繼續滿載,而很閒的永遠都會很閒。
這個問題之所以重要,除了因為我們想要避免資料庫伺服器 CPU 使用量持續過高的狀況之外,我們也希望盡可能透過洽當伺服器數量的方式來降低成本,畢竟每一個資料庫伺服器都相當昂貴。 我們原本以為預先加開伺服器會比較花錢,但根據這邊的觀察,最後其實是沒有預先加開機器的時候,最後才會開了更多的伺服器和花費更多的成本。
就目前而言,我們因為使用的是 AWS 管理的服務,因此演算法沒有其他客製化的可能性。 所以在快取機制上線前的解方,仍然是熱門比賽前要預先加開伺服器。 不過,與公司的是資深前輩聊天的時候,他也提出其實複雜的演算法,最終反而會導致一些預期之外的問題,因此雖然單純的演算法有一些困難,但跟據過往的經驗,我們最後可能還是會選擇相對單純的演算法。
看到這裡,讀者是否有感覺到 SRE 的分析能力的重要性呢?筆者自己認為, SRE 的其中一個特質,就是要有能力看圖說故事。做為一個天橋下的說書人,如何爬疏事件脈落,並整理成有邏輯的故事,也是 SRE 不可惑缺的能力喔。
講完了技術上的發現,接下來也跟各位分享一些與客戶協商的過程。
不知道在上一篇文章中提到的改善策略裡,讀者有沒有覺得有些奇怪?明明說好我們系統的瓶頸是發生在資料庫伺服器上,最後卻還是針對後端伺服器進行預先加開的動作。實際上會有最後的選擇,與之前的例子一樣,都會有一些非技術上的考量。
最主要的問題就會是在於,這個事件本身是源自於我們倒站了大約半小時左右的時間。從客戶的角度來看,他們對於我們所提供的服務的信任度其實是下降的。因此,我們在各種技術上提出來的建議,都會被他們用更保守的方式來進行接下來的討論。
比如說,在評估過後我們雖然認為真正需要加開的其實只有資料庫伺服器, 但是在贏回客戶的信任度之前,我們就會需要連後端伺服器也一起照顧到。此外,我們提出來資料庫伺服器的加開計劃,通常在協商之後,都會加開到比原本計算出來的數量還要更多的狀況,有時候會形成形成一些必要的成本。
但也在經歷過幾次熱門棒球賽都沒有發現意外事件,客戶的信任慢慢被建立回來之後,我們也漸漸能夠用更精準的方式來去設定預先要加開的伺服器數量了。
棒球賽算是筆者第一個遇到比較大,而且也比較重要的日常維運事件之一了。由於它的事發來自於一個重大 P0 事件,再加上棒球賽是一個為時很久又受到客戶重視的活動,因此筆者在這維運事件上也承受了不小的壓力。
不過,筆者也透過這個事件學到了非常多重要的 SRE 能力,包含前面有提到過的分析(看圖說故事)能力,以及和何精準計算大流量下所需要的機器數量等等。另外同樣重要的事情則是,在筆者實際工作的這段時間裡,會發現 SRE 實際上是一個需要花費大量時間溝通的工作,而有時候我們做出來的選擇往往忽視單純技術上的考量。
也正因要處理如此複雜的狀況, SRE 才能顯現出它的價值吧?
下一篇開始,我們會進入另外一個日常維運的主題,關於服務的維護模式。
(10/13更新,因為鐵人賽結束後還有發生新的事件,因此多寫一個鐵人賽的番外篇:https://ithelp.ithome.com.tw/articles/10333864)

